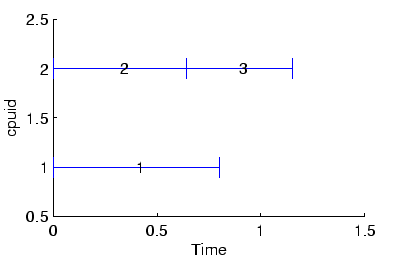
The Parallel Tempering algorithm can suffer from efficiency problems. It is sometimes necessary to run low temperature replicas longer between swap moves. In the case of one replica per processor, this can result in significant idle time while waiting for the lowest temperature replica to complete.
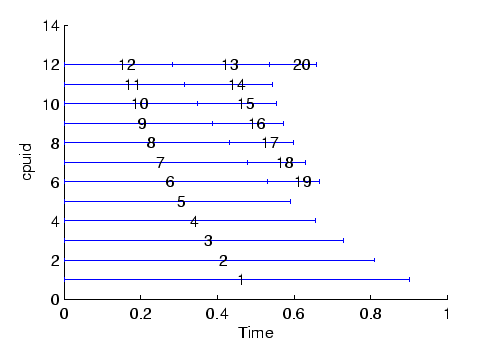
Given that all replicas must complete before a swap move may be considered, scheduling is useful when simulating n replicas on m processers (![]() ). Then it is possible to use what would be idle time to run the higher temperature replicas.
). Then it is possible to use what would be idle time to run the higher temperature replicas.
Scheduling in a parallel environment is a well studied problem. We had planned to look at the scheduleing method proposed by Earl and Deem [9]. The scheduler we actually implimented was a simple on-demand job server.
The scheduler of Earl and Deem is designed so that by construction it will by 100% efficient if replica runtime is consistent. It gets this efficiency by interrupting a job and and finishing it at a later time on another processor. This introduces a fair amount of complexity. Interruptions must be pre-scheduled and dormant replicas must be stored until needed. Additionally unless one has a good estimate for the runtime, the first cycle will be inefficient anyway.
Its advantage is obviously that it is 100% efficient regardless of number of replicas, number of cpus, and relative replica run time. The on-demand scheduler, excepting special cases, is only efficient when ![]() .
.
In both cases run time can be decreased by adding more cpus, but is constrained by the runtime of the longest replica. Gains in "wall clock" runtime from these methods are only realized when the number of available cpus is limited or when avoiding idle time is important.
![]()